Spark SQL Test Doubles
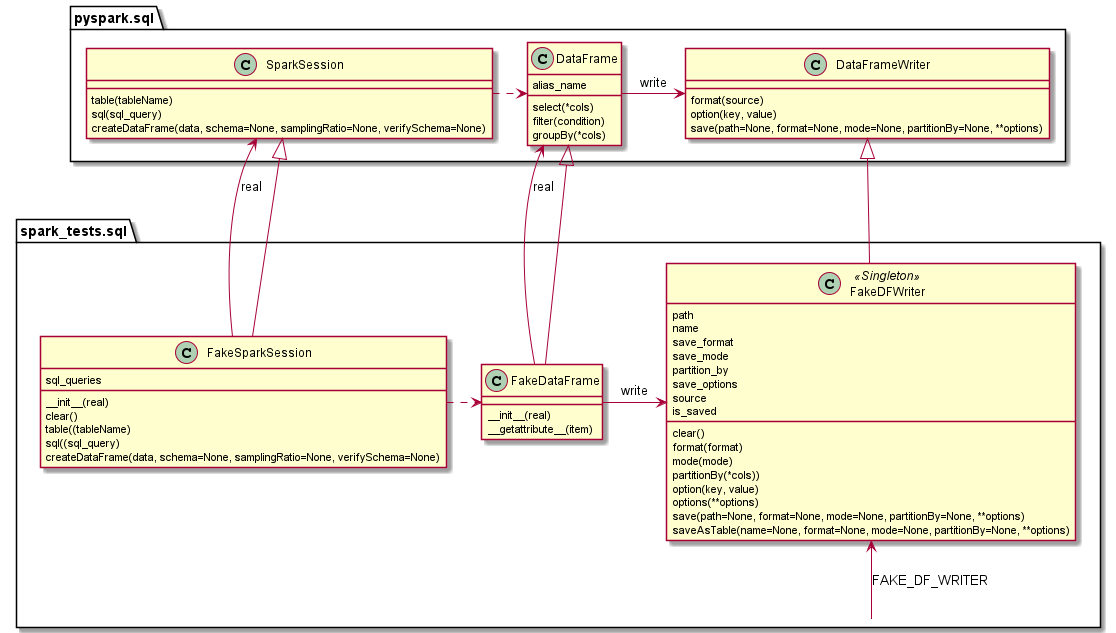
spark-tests.sql module.
Define test classes for Spark SQL:
Queries on data frames are run regularly;
Modification statements are just logged and does not modify data.
- spark_tests.sql.FAKE_DF_WRITER = <spark_tests.sql.FakeDFWriter object>
FakeDFWriter singleton instance.
- class spark_tests.sql.FakeDFWriter
Stubs DataFrameWriter.
Logs the write operation instead of actually writing the data.
Singleton assumes that for each test case there is only one writing.
- path
case writing to a file, the file path
- name
case writing to a table, the table name
- save_format
the format used to save
- source
the source FakeDataFrame
- save_mode
specifies the behavior of the save operation: “error”, “errorifexists”, “append”, “overwrite”, “ignore”
- partition_by
names of partitioning columns
- save_options
all other of partitioning columns
- is_saved
flag of saving execution
- clear()
Clear self to default values.
self.save_format = “parquet”
self.save_mode = “errorifexists”
- format(format: str) FakeDFWriter
Logs format.
- mode(mode: str) FakeDFWriter
Logs mode.
- option(key: str, value: str) FakeDFWriter
Logs a configuration option.
- options(**options: str) FakeDFWriter
Logs configuration options.
- partitionBy(*cols: str) FakeDFWriter
Logs partition columns.
- save(path: Optional[str] = None, format: Optional[str] = None, mode: Optional[str] = None, partitionBy: Optional[List[str]] = None, **options: str) None
Logs current DataFrame rows that would be written to a file.
- saveAsTable(name: str, format: Optional[str] = None, mode: Optional[str] = None, partitionBy: Optional[Union[str, List[str]]] = None, **options: str) None
Logs current DataFrame rows that would be written to a table.
- class spark_tests.sql.FakeDataFrame(real: DataFrame)
DataFrame proxy.
- real
real DataFrame
- alias_name
DataFrame alias name
- property write: FakeDFWriter
Returns FAKE_DF_WRITER.
Set self as the source DataFrame.
- class spark_tests.sql.FakeGroupedData(real: GroupedData)
GroupedData proxy.
- real
real GroupedData.
- agg(*exprs) FakeDataFrame
Compute aggregates.
Delegate to self.real
Return result as a FakeDataFrame
- pivot(pivot_col: str, values: Optional[List[str]] = None) GroupedData
Pivots a column of the current DataFrame.
Delegates to self.real
Return result as a FakeGroupedData
- sum(*cols: str) FakeDataFrame
Compute the sum for each numeric columns for each group.
Delegates to self.real
Return result as FakeDataFrame
- class spark_tests.sql.FakeSparkSession(real: SparkSession)
SparkSession proxy.
Queries on data frames are run regularly;
Modification statements are just logged and does not modify data.
- real
real SparkSession.
- sql_queries
List of modification statements sent.
- clear() None
Clear sql_queries list and FAKE_DF_WRITER
- createDataFrame(data, schema=None) FakeDataFrame
Creates a FakeDataFrame.
Delegates creation to self.real
Returns created DataFrame as a FakeDataFrame
- property sparkContext: SparkContext
Returns SparkContext.
Delegates to self.real.
- sql(sql_statement: str) FakeDataFrame
Logs a sql_statement.
Just appends sql_statement into self.sql_queries with no change to data.
Returns: empty FakeDataFrame.
- Parameters
sql_statement –
- table(table_name: str) FakeDataFrame
Returns specified table as FakeDataFrame.
Delegates to self.real. Result is returned as a FakeDataFrame. This behavior may be changed by subclasses.